Models Have a Limit
0001-01-01
In 2020, OpenAI published Scaling Laws for Neural Language Models. It describes a logarithmic relationship between the accuracy of LLM results, and the number of training tokens, parameters, and compute power. At small scales, LLMs are pointless. But once you gain a few billion parameters, and enough compute, LLMs become super useful. But, then it plateaus - adding more parameters or compute stops improving the model.
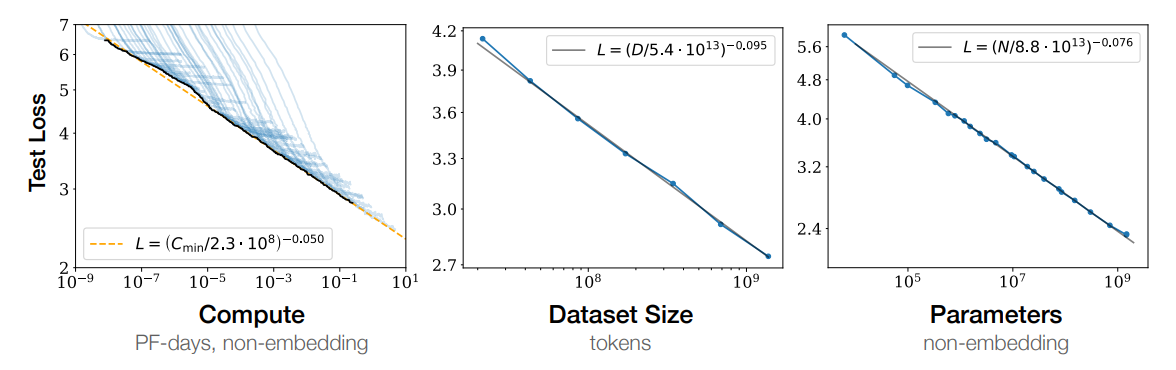
What this ultimately means, is that LLM’s can never be AGI. They are incredibly versatile and useful tools, but there is not enough compute in the universe, not enough tokens in humanity’s history, and not enough parameters that could create AGI. This finding has been replicated year after year - it doesn’t matter what your favorite model is, it’s not AGI.
Worse, they will never be meaningfully better than they are now. We’ve hit the sweet spot in those scaling laws, and you’ve probably noticed that there’s very little change in model quality over the last year. That won’t, can’t, change. This is as good as it gets. When you hear quotes from Ilya (debatably the inventor of LLM’s) like this;
We’re moving from the age of scaling to the age of research
podcast src
This is what he’s expressing. LLM’s aren’t it.
Amodei

Note that Amodei is an author of this paper. He knows that LLM’s aren’t AGI, that the entire founding principle of OpenAI was overhyped. He, and a number of others, left openai that year to found Anthropic. The Claude approach is that [[Architecture Beats Models]] - you don’t need the best model, since that is ultimately a fool’s errand. Instead, a "good enough" model combined with defining architectural standards would give them much better results than pure model work, and position them as the winners of the AI race.
